Publications
Google Scholar | * denotes equal contribution and joint lead authorship.
2026
2026
-
 UOIS Toolkit: A toolkit for unseen object instance segmentation tasksJishnu Jaykumar P, Avaya Aggarwal, and Animesh Maheshwari2026
UOIS Toolkit: A toolkit for unseen object instance segmentation tasksJishnu Jaykumar P, Avaya Aggarwal, and Animesh Maheshwari2026@software{p2026uois_toolkit, title = {UOIS Toolkit: A toolkit for unseen object instance segmentation tasks}, author = {P, Jishnu Jaykumar and Aggarwal, Avaya and Maheshwari, Animesh}, publisher = {GitHub}, journal = {GitHub}, month = apr, year = {2026}, } - iTeach: In the Wild Interactive Teaching for Failure-Driven Adaptation of Robot Perception2026
Robotic perception models often fail in the real world due to clutter, occlusion, and novel objects. Existing approaches rely on offline data collection and retraining — slow, and blind to deployment-time failures. We propose iTeach, a failure-driven interactive teaching framework that adapts robot perception in the wild. A co-located human observes live predictions, triggers a short HumanPlay interaction on a failed object, and records an RGB-D sequence. Our Few-Shot Semi-Supervised (FS3) labeling annotates only the final frame using hands-free eye-gaze and voice; SAM2 propagates the mask across the sequence for dense supervision. Iterative fine-tuning on these samples progressively improves an MSMFormer UOIS model, translating into higher grasping and pick-and-place success on the SceneReplica benchmark and real-robot experiments.
@misc{p2026iteachwildinteractiveteaching, title = {iTeach: In the Wild Interactive Teaching for Failure-Driven Adaptation of Robot Perception}, author = {P, Jishnu Jaykumar and Salvato, Cole and Bomnale, Vinaya and Wang, Jikai and Xiang, Yu}, year = {2026}, eprint = {2410.09072}, archiveprefix = {arXiv}, primaryclass = {cs.RO}, journal = {arXiv}, }
2025
2025
- HRT1: One-Shot Human-to-Robot Trajectory Transfer for Mobile ManipulationarXiv, 2025
We introduce a novel system for human-to-robot trajectory transfer that enables robots to manipulate objects by learning from human demonstration videos. The system consists of four modules. The first module is a data collection module that is designed to collect human demonstration videos from the point of view of a robot using an AR headset. The second module is a video understanding module that detects objects and extracts 3D human-hand trajectories from demonstration videos. The third module transfers a human-hand trajectory into a reference trajectory of a robot end-effector in 3D space. The last module utilizes a trajectory optimization algorithm to solve a trajectory in the robot configuration space that can follow the end-effector trajectory transferred from the human demonstration. Consequently, these modules enable a robot to watch a human demonstration video once and then repeat the same mobile manipulation task in different environments, even when objects are placed differently from the demonstrations.
@article{2025hrt1, title = {HRT1: One-Shot Human-to-Robot Trajectory Transfer for Mobile Manipulation}, author = {Allu*, Sai Haneesh and P*, Jishnu Jaykumar and Khargonkar, Ninad and Summers, Tyler and Yao, Jian and Xiang, Yu}, primaryclass = {cs.RO}, journal = {arXiv}, year = {2025}, } - Adapting Pre-Trained Vision Models for Novel Instance Detection and SegmentationIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025
Novel Instance Detection and Segmentation (NIDS) aims at detecting and segmenting novel object instances given a few examples of each instance. We propose a unified framework (NIDS-Net) comprising object proposal generation, embedding creation for both instance templates and proposal regions, and embedding matching for instance label assignment. Leveraging recent advancements in large vision methods, we utilize the Grounding DINO and Segment Anything Model (SAM) to obtain object proposals with accurate bounding boxes and masks. Central to our approach is the generation of high-quality instance embeddings. We utilize foreground feature averages of patch embeddings from the DINOv2 ViT backbone, followed by refinement through a weight adapter mechanism that we introduce. We show experimentally that our weight adapter can adjust the embeddings locally within their feature space and effectively limit overfitting. This methodology enables a straightforward matching strategy, resulting in significant performance gains. Our framework surpasses current state-of-the-art methods, demonstrating notable improvements of 22.3, 46.2, 10.3, and 24.0 in average precision (AP) across four detection datasets. In instance segmentation tasks on seven core datasets of the BOP challenge, our method outperforms the top RGB methods by 3.6 AP and remains competitive with the best RGB-D method.
@inproceedings{lu2024adapting, title = {Adapting Pre-Trained Vision Models for Novel Instance Detection and Segmentation}, author = {Lu, Yangxiao and P, Jishnu Jaykumar and Guo, Yunhui and Ruozzi, Nicholas and Xiang, Yu}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, year = {2025}, }
2024
2024
- Proto-CLIP: Vision-Language Prototypical Network for Few-Shot LearningIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024
We propose a novel framework for few-shot learning by leveraging large-scale vision-language models such as CLIP. Motivated by the unimodal prototypical networks for few-shot learning, we introduce PROTO-CLIP that utilizes image prototypes and text prototypes for few-shot learning. Specifically, PROTO-CLIP adapts the image encoder and text encoder in CLIP in a joint fashion using few-shot examples. The two encoders are used to compute prototypes of image classes for classification. During adaptation, we propose aligning the image and text prototypes of corresponding classes. Such a proposed alignment is beneficial for few-shot classification due to the contributions from both types of prototypes. We demonstrate the effectiveness of our method by conducting experiments on benchmark datasets for few-shot learning as well as in the real world for robot perception.
@inproceedings{padalunkal2024protoclip, author = {P, Jishnu Jaykumar and Palanisamy, Kamalesh and Chao, Yu-Wei and Du, Xinya and Xiang, Yu}, title = {{Proto-CLIP: Vision-Language Prototypical Network for Few-Shot Learning}}, keywords = {Training;Representation learning;Adaptation models;Three-dimensional displays;Prototypes;Benchmark testing;Object recognition;Few shot learning;Intelligent robots}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, doi = {10.1109/IROS58592.2024.10801660}, pages = {2594-2601}, year = {2024}, } - SceneReplica: Benchmarking Real-World Robot Manipulation by Creating Replicable ScenesNinad Khargonkar*, Sai Haneesh Allu*, Yangxiao Lu, Jishnu Jaykumar P, Balakrishnan Prabhakaran, and Yu XiangIn IEEE International Conference on Robotics and Automation (ICRA), 2024
We present a new reproducible benchmark for evaluating robot manipulation in the real world, specifically focusing on the task of pick-and-place. Our benchmark uses the YCB objects, a commonly used dataset in the robotics community, to ensure that our results are comparable to other studies. Additionally, the benchmark is designed to be easily reproducible in the real world, making it accessible for researchers and practitioners. We also provide our experimental results and analyses for model-based and model-free 6D robotic grasping on the benchmark, where representative algorithms for object perception, grasping planning and motion planning are evaluated. We believe that our benchmark will be a valuable tool for advancing the field of robot manipulation. By providing a standardized evaluation framework, researchers can more easily compare different techniques and algorithms, leading to faster progress in developing robot manipulation methods.
@inproceedings{khargonkar2024scenereplica, author = {Khargonkar*, Ninad and Allu*, Sai Haneesh and Lu, Yangxiao and P, Jishnu Jaykumar and Prabhakaran, Balakrishnan and Xiang, Yu}, booktitle = {IEEE International Conference on Robotics and Automation (ICRA)}, title = {{SceneReplica: Benchmarking Real-World Robot Manipulation by Creating Replicable Scenes}}, year = {2024}, volume = {}, number = {}, pages = {8258-8264}, keywords = {Analytical models;Focusing;Grasping;Benchmark testing;Planning;Task analysis;Robots}, doi = {10.1109/ICRA57147.2024.10610180}, }

2023
2023
-
 FewSOL: A Dataset for Few-Shot Object Learning in Robotic EnvironmentsJishnu Jaykumar P, Yu-Wei Chao, and Yu XiangIn IEEE International Conference on Robotics and Automation (ICRA), 2023
FewSOL: A Dataset for Few-Shot Object Learning in Robotic EnvironmentsJishnu Jaykumar P, Yu-Wei Chao, and Yu XiangIn IEEE International Conference on Robotics and Automation (ICRA), 2023We introduce the Few-Shot Object Learning (FEWSOL) dataset for object recognition with a few images per object. We captured 336 real-world objects with 9 RGB-D images per object from different views. Fewsol has object segmentation masks, poses, and attributes. In addition, synthetic images generated using 330 3D object models are used to augment the dataset. We investigated (i) few-shot object classification and (ii) joint object segmentation and few-shot classification with state-of-the-art methods for few-shot learning and meta-learning using our dataset. The evaluation results show the presence of a large margin to be improved for few-shot object classification in robotic environments, and our dataset can be used to study and enhance few-shot object recognition for robot perception. Dataset and code available at https://irvlutd.github.io/FewSOL.
@inproceedings{padalunkal2023fewsol, title = {{FewSOL: A Dataset for Few-Shot Object Learning in Robotic Environments}}, author = {P, Jishnu Jaykumar and Chao, Yu-Wei and Xiang, Yu}, booktitle = {IEEE International Conference on Robotics and Automation (ICRA)}, doi = {10.1109/ICRA48891.2023.10161143}, pages = {9140-9146}, year = {2023}, } -
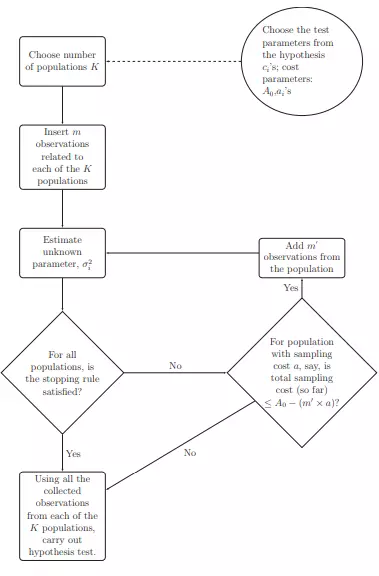 A sequential approach for noninferiority or equivalence of a linear contrast under cost constraints.Psychological Methods, 2023
A sequential approach for noninferiority or equivalence of a linear contrast under cost constraints.Psychological Methods, 2023Planning an appropriate sample size for a study involves considering several issues. Two important considerations are cost constraints and variability inherent in the population from which data will be sampled. Methodologists have developed sample size planning methods for two or more populations when testing for equivalence or noninferiority/superiority for a linear contrast of population means. Additionally, cost constraints and variance heterogeneity among populations have also been considered. We extend these methods by developing a theory for sequential procedures for testing the equivalence or noninferiority/superiority for a linear contrast of population means under cost constraints, which we prove to effectively utilize the allocated resources. Our method, due to the sequential framework, does not require prespecified values of unknown population variance(s), something that is historically an impediment to designing studies. Importantly, our method does not require an assumption of a specific type of distribution of the data in the relevant population from which the observations are sampled, as we make our developments in a data distribution-free context. We provide an illustrative example to show how the implementation of the proposed approach can be useful in applied research.
@article{chattopadhyay2023sequential, title = {A sequential approach for noninferiority or equivalence of a linear contrast under cost constraints.}, author = {Chattopadhyay, Bhargab and Bandyopadhyay, Tathagata and Kelley, Ken and Padalunkal, Jishnu J}, journal = {Psychological Methods}, year = {2023}, publisher = {American Psychological Association}, doi = {https://doi.org/10.1037/met0000570} }


2021
2021
-
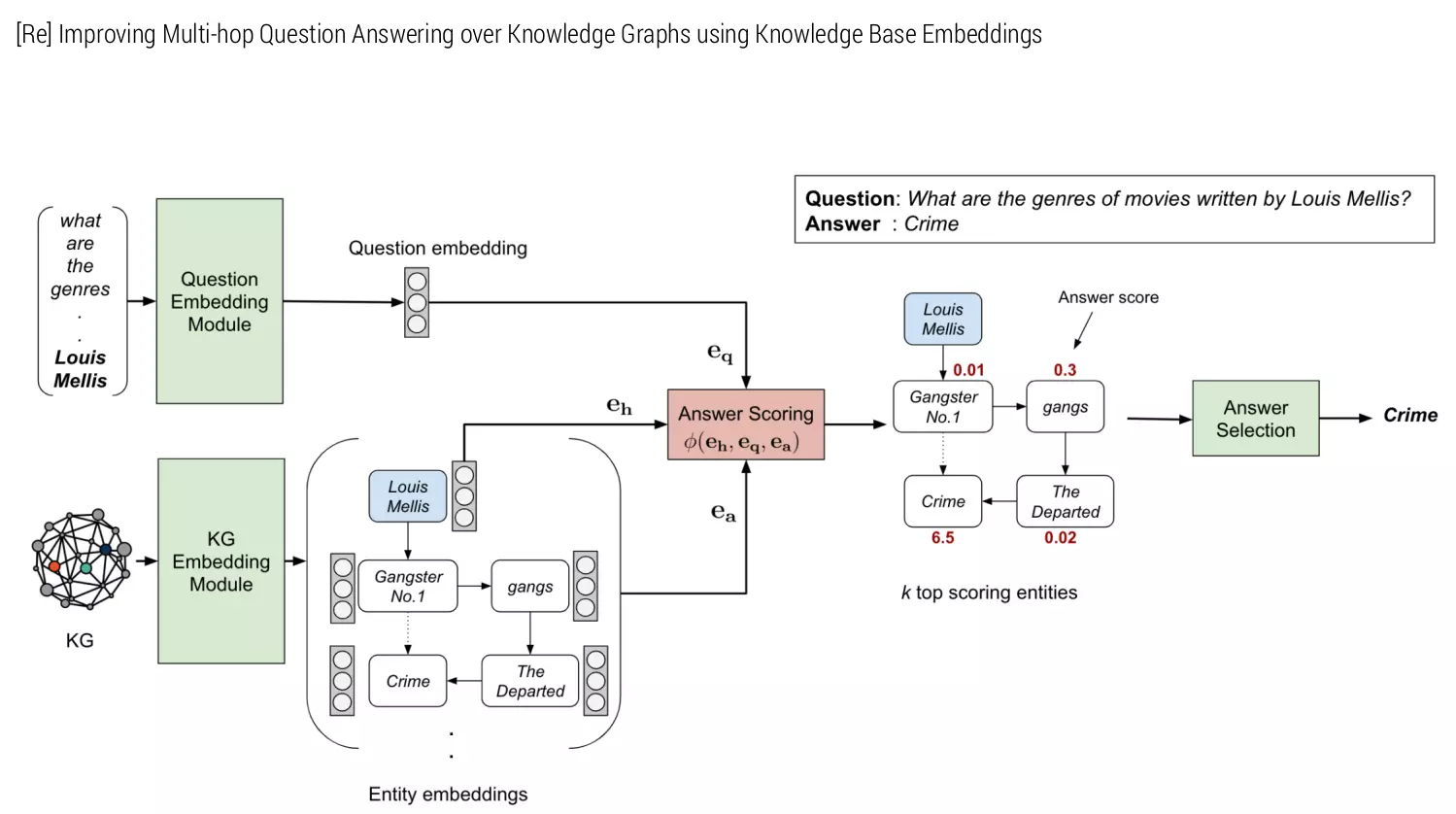 [Re] Improving Multi-hop Question Answering over Knowledge Graphs using Knowledge Base EmbeddingsJishnu Jaykumar P, and Ashish Sardana2021
[Re] Improving Multi-hop Question Answering over Knowledge Graphs using Knowledge Base EmbeddingsJishnu Jaykumar P, and Ashish Sardana2021Our work consists of four parts: (1) Reproducing results from Saxena et al. [2020] (2) Adding more experiments by replacing the knowledge graph embedding method (3) and exploring the question embedding method using various transformer models (4) Verifying the importance of Relation Matching (RM) module. Based on the code shared by the authors, we have reproduced the results for the EmbedKGQA method. We have not purposely performed relation matching to validate point-4.
@article{P2021, title = {[{Re}] {Improving} {Multi}-hop {Question} {Answering} over {Knowledge} {Graphs} using {Knowledge} {Base} {Embeddings}}, author = {P, Jishnu Jaykumar and Sardana, Ashish}, journal = {ReScience C}, publisher = {ReScience C}, url = {https://zenodo.org/record/4834942}, doi = {10.5281/ZENODO.4834942}, volume = {7}, issue = {2}, number = {#15}, review_url = {https://openreview.net/forum?id=VFAwCMdWY7}, month = may, year = {2021}, type = {Replication}, language = {Python}, domain = {ML Reproducibility Challenge 2020}, keywords = {knowledge graph, embeddings, multi-hop, question-answering, deep learning}, } -
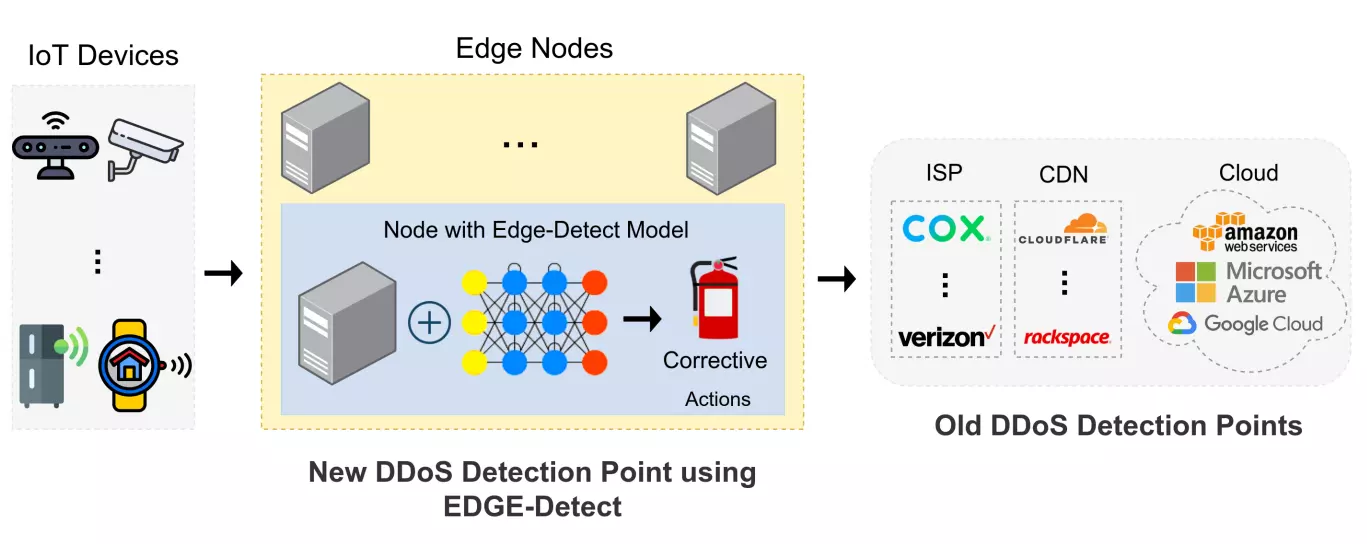 Edge-Detect: Edge-Centric Network Intrusion Detection using Deep Neural NetworkIn IEEE Annual Consumer Communications & Networking Conference (CCNC), 2021
Edge-Detect: Edge-Centric Network Intrusion Detection using Deep Neural NetworkIn IEEE Annual Consumer Communications & Networking Conference (CCNC), 2021Edge nodes are crucial for detection against multitudes of cyber attacks on Internet-of-Things endpoints and is set to become part of a multi-billion industry. The resource constraints in this novel network infrastructure tier constricts the deployment of existing Network Intrusion Detection System with Deep Learning models (DLM). We address this issue by developing a novel light, fast and accurate ‘Edge-Detect’ model, which detects Distributed Denial of Service attack on edge nodes using DLM techniques. Our model can work within resource restrictions i.e. low power, memory and processing capabilities, to produce accurate results at a meaningful pace. It is built by creating layers of Long Short-Term Memory or Gated Recurrent Unit based cells, which are known for their excellent representation of sequential data. We designed a practical data science pipeline with Recurring Neural Network to learn from the network packet behavior in order to identify whether it is normal or attack-oriented. The model evaluation is from deployment on actual edge node represented by Raspberry Pi using current cybersecurity dataset (UNSW2015). Our results demonstrate that in comparison to conventional DLM techniques, our model maintains a high testing accuracy of 99% even with lower resource utilization in terms of cpu and memory. In addition, it is nearly 3 times smaller in size than the state-of-art model and yet requires a much lower testing time.
@inproceedings{singh2021edgedetect, author = {Singh*, Praneet and P*, Jishnu Jaykumar and Pankaj, Akhil and Mitra, Reshmi}, booktitle = {IEEE Annual Consumer Communications \& Networking Conference (CCNC)}, title = {{Edge-Detect: Edge-Centric Network Intrusion Detection using Deep Neural Network}}, year = {2021}, pages = {1-6}, doi = {10.1109/CCNC49032.2021.9369469}, }


2018
2018
-
 MV-Tractus: A simple tool to extract motion vectors from H264 encoded video sourcesJishnu P, and Praneet Singh2018
MV-Tractus: A simple tool to extract motion vectors from H264 encoded video sourcesJishnu P, and Praneet Singh2018@software{p_mvtractus_2018, publisher = {Zenodo}, author = {P, Jishnu and Singh, Praneet}, journal = {Zenodo}, month = oct, year = {2018}, version = {2.0}, doi = {10.5281/zenodo.4422613}, }
